The world’s first caesium-133 atomic clock (1955), and otherwise unrelated everything else here.
The world’s first caesium-133 atomic clock (1955), and otherwise unrelated everything else here.
This was originally authored by Spencer Kimball about four years ago; I tried re-writing it to understand it better. You’ll also find it on our company engineering blog. To keep up with new writing, sign up for my (entirely inactive) newsletter.
One of the more inspired facets of Spanner1 comes from its use of atomic clocks to give participating nodes really accurate wall time synchronization. The designers of Spanner call this TrueTime, and it provides a tight bound on clock offset between any two nodes in the system. This lets them do pretty nifty things! We’ll elaborate on a few of these below, but chief among them is their ability to leverage tightly synchronized clocks to provide a high level of external consistency (we’ll explain what this is too).
Seeing as how CockroachDB2 (abbrev.
It’s a good question, and one we (try) to elaborate on here. As a
Spanner-derived system, our challenges lie in providing similar guarantees of
external consistency without having these magical clocks at hand.
So what does
1. Time in Distributed Systems
Time is a fickle thing. For readers unfamiliar with the complexities around time in distributed systems research, the thing to know about it all is this: each node in the system maintains its own view of time, usually powered by its own on-chip clock device. This clock device is rarely ever going to be perfectly in sync with other nodes in the system, and as such, there’s no absolute time to refer to.
Existentialism aside, perfectly synchronized clocks are a holy grail of sorts for distributed systems research. They provide, in essence, a means to absolutely order events, regardless of which node an event originated at. This can be especially useful when performance is at stake, allowing subsets of nodes to make forward progress without regard to the rest of the cluster (seeing as every other node is seeing the same absolute time), while still maintaining global ordering guarantees. Our favorite Turing award winner has written a few words on the subject3.
2. Linearizability
By contrast, systems without perfectly synchronized clocks (read: every system) that wish to establish a complete global ordering must communicate with a single source of time on every operation. This was the motivation behind the timestamp oracle as used by Google’s Percolator4. A system which orders transactions \(T_1\) and \(T_2\) in the order \([T_1, T_2]\) provided that \(T_2\) starts after \(T_1\) finishes, regardless of observer, provides for the strongest guarantee of consistency called external consistency5. To confuse things further, this is what folks interchangeably refer to as linearizability or strict serializability. Andrei has more words on this soup of consistency models here.
3. Serializability
Let’s follow one more tangent and introduce the concept of serializability.
Most database developers are familiar with serializability as the highest
isolation level provided by the
In a non-distributed database, serializability implies linearizability for transactions because a single node has a monotonically increasing clock (or should, anyway!). If transaction \(T_1\) is committed before starting transaction \(T_2\), then transaction \(T_2\) can only commit at a later time.
In a distributed database, things can get dicey. It’s easy to see how the ordering of causally-related transactions can be violated if nodes in the system have unsynchronized clocks. Assume there are two nodes, \(N_1\) and \(N_2\), and two transactions, \(T_1\) and \(T_2\), committing at \(N_1\) and \(N_2\) respectively. Because we’re not consulting a single, global source of time \(t\), transactions use the node-local clocks to generate commit timestamps \(ts\). To illustrate the trickiness around this stuff, let’s say \(N_1\) has an accurate one but \(N_2\) has a clock lagging by \(100ms\). We start with \(T_1\), addressing \(N_1\), which is able to commit at \(ts = 150ms\). An external observer sees \(T_1\) commit and consequently starts \(T_2\), addressing \(N_2\), \(50ms\) later (at \(t = 200ms\)). Since \(T_2\) is annotated using the timestamp retrieved from \(N_2\)’s lagging clock, it commits in the past, at \(ts = 100ms\). Now, any observer reading keys across \(N_1\) and \(N_2\) will see the reversed ordering, \(T_2\)’s writes (at \(ts = 100ms\)) will appear to have happened before \(T_1\)’s (at \(ts = 150ms\)), despite the opposite being true. ¡No bueno! (Note that this can only happen when the two transactions access a disjoint set of keys.)
Causally related transactions committing out of order due to unsynchronized clocks.
Figure 1. Causally related transactions committing out of order due to unsynchronized clocks.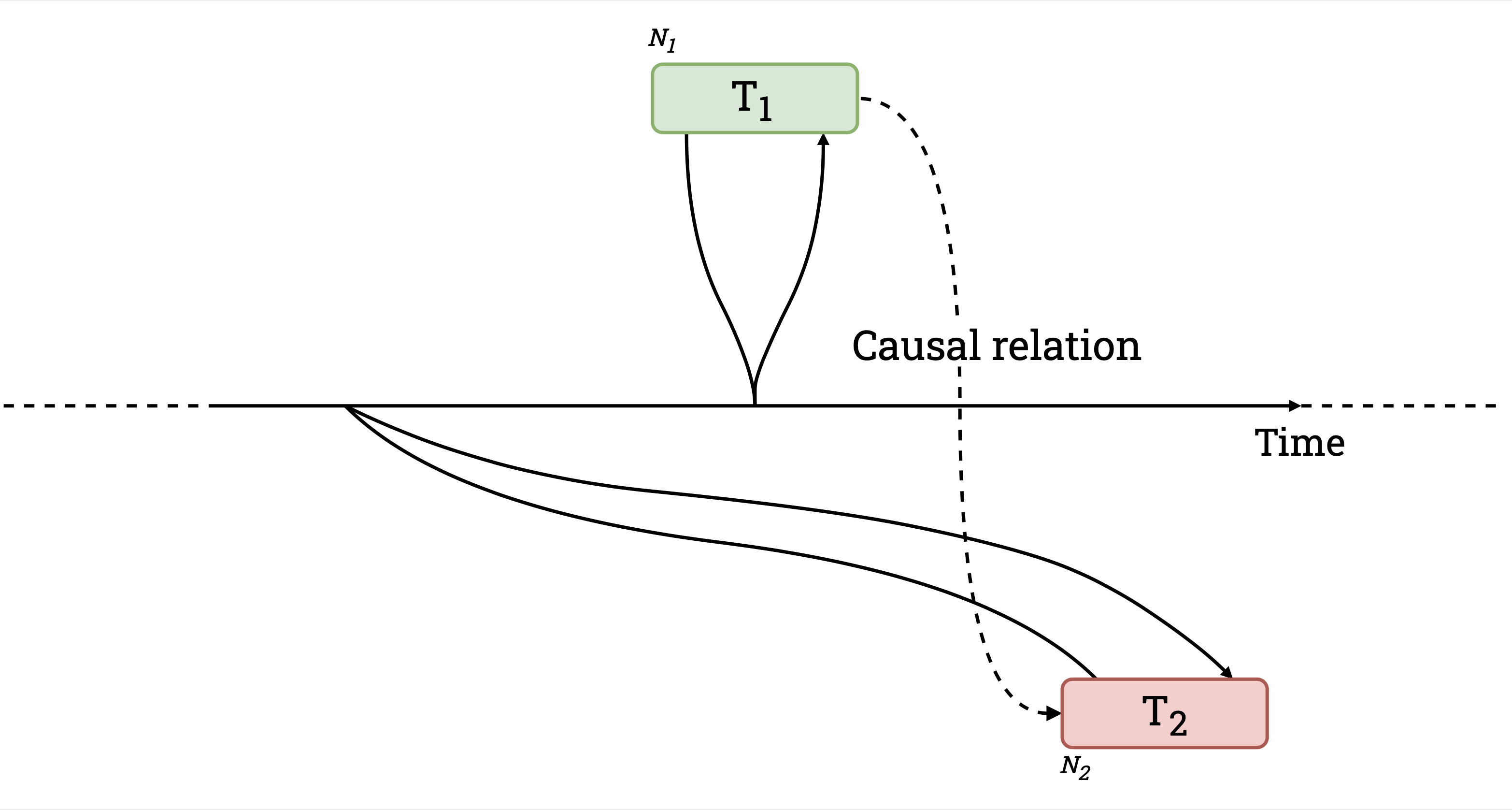
The anomaly described here, and shown in the figure above, is something we call
causal reverse. While Spanner provides linearizability,
4. How does TrueTime provide linearizability?
So, back to Spanner and TrueTime. It’s important to keep in mind that TrueTime
does not guarantee perfectly synchronized clocks. Rather, TrueTime gives an
upper bound for clock offsets between nodes in a cluster. The use of
synchronized atomic clocks is what helps minimize the upper bound. In Spanner’s
case, Google mentions an upper bound of 7ms. That’s pretty tight; by contrast,
using
So how does Spanner use TrueTime to provide linearizability given that there are still inaccuracies between clocks? It’s actually surprisingly simple. It waits. Before a node is allowed to report that a transaction has committed, it must wait 7ms. Because all clocks in the system are within 7ms of each other, waiting 7ms means that no subsequent transaction may commit at an earlier timestamp, even if the earlier transaction was committed on a node with a clock which was fast by the maximum 7ms. Pretty clever.
Careful readers will observe that the whole wait out the uncertainty idea is
not predicated on having atomic clocks lying around. One could very well wait
out the maximum clock offset in any system and achieve linearizability. It
would of course be impractical to have to eat
Fun fact: early
5. How important is linearizability?
Stronger guarantees are a good thing, but some are more useful than others. The possibility of reordering commit timestamps for causally related transactions is likely a marginal problem in practice. What could happen is that examining the database at a historical timestamp might yield paradoxical situations where transaction \(T_1\) is not yet visible while transaction \( T_2\) is, even though transaction \(T_1\) is known to have preceded \(T_2\), as they’re causally related. However, this can only happen if (a) there’s no overlap between the keys read or written during the transactions, and (b) there’s an external low-latency communication channel between clients that could potentially impact activity on the database.
For situations where reordering could be problematic,
But there’s a more critical use for TrueTime than ordering transactions. When
starting a transaction reading data from multiple nodes, a timestamp must be
chosen which is guaranteed to be at least as large as the highest commit time
across all nodes. If that’s not true, then the new transaction might fail to
read already-committed data – an unacceptable breach of consistency. With
TrueTime at your disposal, the solution is easy; simply choose the current
TrueTime. Since every already-committed transaction must have committed at
least 7ms ago, the current node’s wall clock must have a time greater than or
equal to the most recently committed transaction. Wow, that’s easy and
efficient. So what does
6. How does CockroachDB choose transaction timestamps?
The short answer? Something not as easy and not as efficient. The longer answer
is that
As mentioned earlier, the timestamp we choose for the transaction must be
greater than or equal to the maximum commit timestamp across all nodes we
intend to read from. If we knew the nodes which would be read from in advance,
we could send a parallel request for the maximum timestamp from each and use
the latest. But this is a bit clumsy, since
What
While Spanner always waits after writes, CockroachDB sometimes waits before reads.
When
As the transaction reads data from various nodes, it proceeds without
difficulty so long as it doesn’t encounter a key written within this interval.
If the transaction encounters a value at a timestamp below its provisional
commit timestamp, it trivially observes the value during reads and overwrites
the value at the higher timestamp during writes. It’s only when a value is
observed to be within the uncertainty interval that
As mentioned above, the contrast between Spanner and
Because
8. Concluding thoughts
If you’ve made it this far, thanks for hanging in there. If you’re new to it all, this is tricky stuff to grok. Even we occasionally need reminding about how it all fits together, and we built the damn thing.
- James C. Corbett, Jeffrey Dean, et. al. 2012. Spanner: Google’s Globally-Distributed Database. ⤻
- Rebecca Taft, Irfan Sharif et. al. 2020. CockroachDB: The Resilient Geo-Distributed SQL Database. ⤻
- Barbara Liskov. 1991. Practical uses of synchronized clocks in distributed systems. ⤻
- Daniel Peng, Frank Dabek. 2010. Large-scale Incremental Processing Using Distributed Transactions and Notifications. ⤻
- David Kenneth Gifford. 1981. Information storage in a decentralized computer system. ⤻
- Yilong Geng, Shiyu Liu, et. al. 2018. Exploiting a Natural Network Effect for Scalable, Fine-grained Clock Synchronization ⤻
- Daniel Abadi et. al. 2012. Calvin: Fast Distributed Transactions for Partitioned Database Systems. ⤻
- Daniel Abadi et. al. 2019. SLOG: Serializable, Low-latency, Geo-replicated Transactions. ⤻