The world’s most powerful computer (1954) at Columbia University’s Watson Lab.
The world’s most powerful computer (1954) at Columbia University’s Watson Lab.
Spoke with our interns this year to understand what they were working on. Some version of this will post eventually find its way to the company’s engineering blog. To keep up with new writing, sign up for my newsletter.
While not exactly envious of our current crop of interns (cause, you know,
the whole work from home thing), I’ll admit I find myself reminiscing back to
when I was one myself. I’m still surprised they let me anywhere near the stuff
they did. When I first interned four years ago, we had just declared a code yellow
to focus our energy towards stabilizing SUM, COUNT, DISTINCT,
etc.), and various sorting algorithms.
That was more than enough to rope me back in for a second internship. This time I brought my dear friend Bilal along, who similarly went on to intern twice. I even managed to sneak my brother in (a strictly worse engineer), also as a two-time intern.
All of which is to say that I think internships here can be pretty great.
We hosted several interns over the year across various engineering teams, all working on projects deserving of full-length blog posts. Today however we’ll highlight two projects from our most recent batch and give a briefer treatment for the remaining.
1. Read-based compaction heuristics
Aaditya Sondhi interned on our Storage team
to work on Pebble,
a storage engine based on log-structured merge trees34
(abbrev.
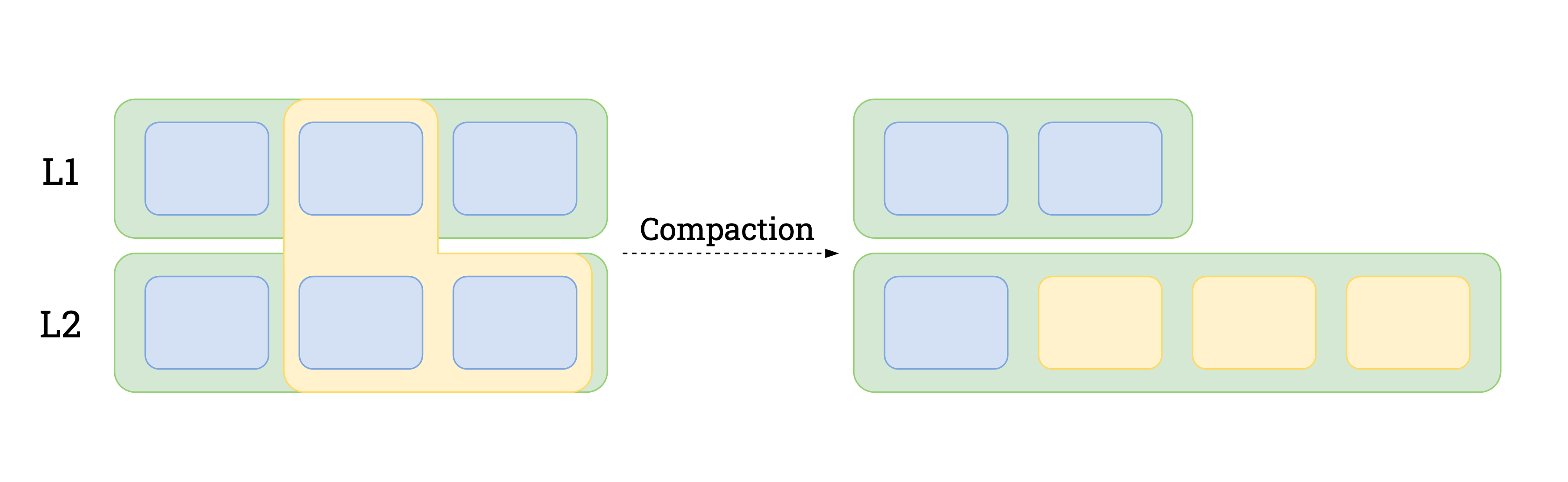
1.1 Compactions and read-amplification in LSMs
In k from a two-level
That in turn brings us to compactions5. As data flows into higher
level
An
(Aside: there’s something to be said about how storage engines are
characterized in terms of resource utilization10 as opposed to
unqualified throughput or latency. System-wide measures like $/tpmC11
are another example of this. These feel comparatively easier to reason about,
more useful for capacity planning, and easily verifiable.)
1.2 Optimizing compactions for read-amplification
Compacting
We hypothesized that by scheduling compactions for oft-read key ranges, we
could lower read amplification for subsequent reads, thus lowering resource
utilization and improving read performance. In implementing it,
we borrowed from the ideas present in google/leveldb.
For every positioning operation that returned a user key (think Next, Prev,
Seek, etc.), we sampled the key range (mediated by tunable knobs). The
sampling process checked for overlapping
Benchmarks showing the effect of read-based compactions on throughput, read-amplification and write-amplification.
$ benchstat baseline-1024.txt read-compac-1024.txt
old ops/sec new ops/sec delta
ycsb/C/values=1024 605k ± 8% 1415k ± 5% +133.93% (p=0.008 n=5+5)
old r-amp new r-amp delta
ycsb/C/values=1024 4.28 ± 1% 1.24 ± 0% -71.00% (p=0.016 n=5+4)
old w-amp new w-amp delta
ycsb/C/values=1024 0.00 0.00 ~ (all equal)
$ benchstat baseline-64.txt read-compac-64.txt
old ops/sec new ops/sec delta
ycsb/B/values=64 981k ±11% 1178k ± 2% +20.14% (p=0.016 n=5+4)
old r-amp new r-amp delta
ycsb/B/values=64 4.18 ± 0% 3.53 ± 1% -15.61% (p=0.008 n=5+5)
old w-amp new w-amp delta
ycsb/B/values=64 4.29 ± 1% 14.86 ± 3% +246.80% (p=0.008 n=5+5)Figure 2. Benchmarks showing the effect of read-based compactions on throughput, read-amplification and write-amplification.
As expected, we found
that read-based compactions led to significant improvement in read heavy
workloads. Our benchmarks running
2. Query denylists (and our RFC process)
Angela Wen interned on our
Angela’s experience captures the kind of broad leeway accorded to
interns that I’m arguing we do a bit better than elsewhere. A general purpose
query denylist is a
very open-ended problem, with many personas you could design it for, and one
took deliberate effort to build consensus on. The process
we use to structure these conversations are
The
We ended up eschewing our original proposal to implement file-mounted regex-based denylists (the contentions here being around usability, deployment, etc.) in favor of cluster settings of the form:
SET CLUSTER SETTING feature.changefeed.enabled = FALSE;
SET CLUSTER SETTING feature.schema_change.enabled = TRUE;Configuration changes were made to disseminate cluster-wide by means of gossip14. Individual nodes listen in on these updates use the deltas to keep an in-memory block-cache (sorry) up-to-date. This is later checked against during query execution to determine whether or it’s an allowable operation.
Like mentioned earlier, we scrapped lots of alternate designs during this process, and were better off for it. We re-sized our scope to focus instead on certain classes of queries as opposed to more granularly matching specific ones. This came after observing that a vast majority of problematic queries during prior incidents were well understood, and could be structurally grouped/gated wholesale. That said, we modularized our work to make it simple to introduce new categories as needed.
3. Observability, design tokens, data-loss repair, and more
We hosted a few other interns this semester, and there’s much to be said about their individual contributions. We typically structure our programs to have folks work on one or two major projects, building up to them with starter ones. Here we’ll briefly touch what these were.
3.1 Query runtime statistics
The query execution plan for a full table scan followed by an AVG.
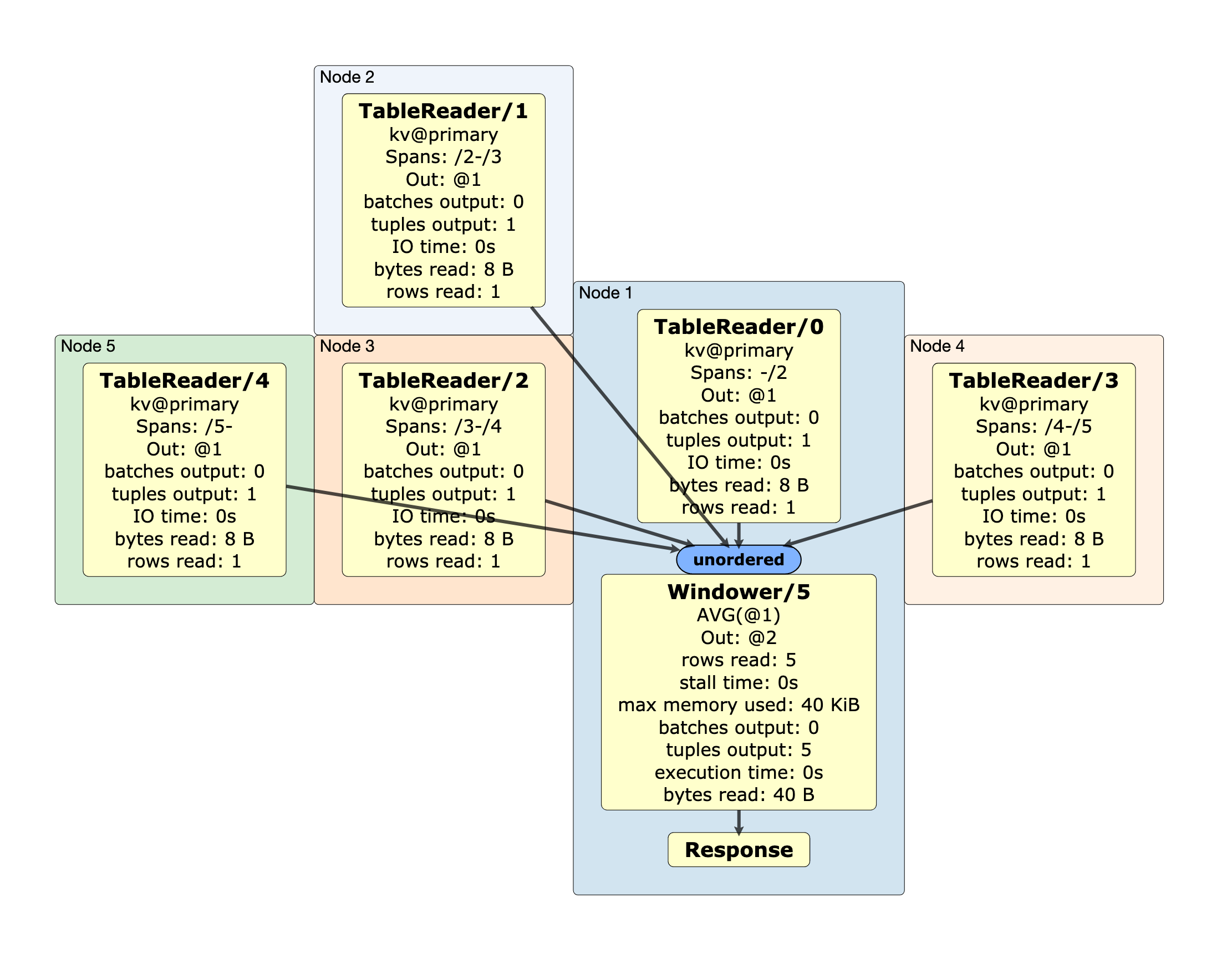
AVG.
Cathy Wang interned on our SQL Execution team and worked on improving observability for running queries. We have some existing infrastructure in place to surface various execution statistics. Cathy built upon this to include details about network latencies (useful for debugging queries run within geo-distributed clusters), structured our traces to break down how much time is spent across various layers in the system, and tacked on memory utilization to our traces to surface exactly how much memory is in-use during any point mid-execution. This last bit is worth elaborating on: Go’s garbage collector doesn’t give us fine-grained control over allocations, and to that end a result we’ve had to design our own memory accounting/monitoring infrastructure to closely track usage during a query’s lifecycle. By exposing these internal statistics, we expect developers to better understand the memory footprint of individual queries and to tune them accordingly.
3.2 Design tokens
Pooja Maniar interned within the
Cloud organization, specifically on the Console team. One of the projects she
worked on was consolidating and standardizing our design
tokens. Think of these as
abstractions over visual properties, variables to replace hardcoded color
palettes, fonts, box shadows on pressed buttons, etc. The motivation here was
to limit the number of design decisions developers had to
make, whether it be choosing between specific hexcodes,
3.3 Quorum recovery
Sam Huang interned on the
3.4 Metamorphic schema changes
Jayant Shrivastava interned on our SQL Schemas
team, and spent his time here ruggedizing our schemas infrastructure.
3.5 Import compatibility
Monica Xu took a brief hiatus from her aspiring music
career to intern on our Bulk IO team. Her team’s
broadly responsible for getting data in and out of pg_dump16 compatibility. There were kinks to be work out
with the latter seeing as how pg_dump files as
is. The particular set of questions Monica helped address was what
reasonable behavior is when chewing through potentially destructive import
directives. Think DROP TABLE [IF EXISTS], or CREATE VIEW, which is
particularly tricky given it stores the results of the query it was constructed
using, results subject to change during the import process. Monica engaged with
our product teams when forming these judgements (we now simply defer to the user
with instructive messaging), and helped significantly
ease the onboarding
experience for developers migrating off of their existing installations.
4. Parting thoughts
If you’re still here and interested, hit us up. And don’t let the database-speak throw you off, most of us didn’t know any of it coming in.
- Radu Berinde, Andrei Matei. 2016. Distributing SQL Queries in CockroachDB. ⤻
- Raphael Poss. 2017. On the Way to Better SQL Joins in CockroachDB ⤻
- Arjun Narayan, 2018. A Brief History of Log Structured Merge Trees. ⤻
- Arjun Narayan, Peter Mattis. 2019. Why we built CockroachDB on top of RocksDB. ⤻
- Siying Dong, [n.d.]. Leveled Compactions in RocksDB. ⤻
- Mark Callaghan, 2018. Read, Write & Space Amplification – Pick Two. ⤻
- Mark Callaghan, 2018. Describing Tiered and Leveled Compactions. ⤻
- Mark Callaghan, 2018. Name that Compaction Algorithm. ⤻
- Mark Callaghan, 2018. Tiered or Leveled Compactions, Why Not Both?. ⤻
- Nelson Elhage, 2020. Performance as Hardware Utilization. ⤻
- TPC-C, [n.d.]. What is TPC-C. ⤻
- Mike Ulrich, 2017. Site Reliability Engineering, Addressing Cascading Failures. ⤻
- Martin Fowler, 2014. Circuit Breakers. ⤻
- Abhinandan Das, Indranil Gupta, et. al. 2002. SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol. ⤻
- Kyle Kingsbury, 2016. Jepsen Testing CockroachDB. ⤻
- PostgreSQL 9.6.20 Documentation, [n.d.].
pg_dump. ⤻